GEPA is Better Than You Think
GEPA (Genetic Pareto) is one of the most popular automatic prompt optimization methods right now, and it recently got accepted to ICLR 2026 as an oral paper. To see how widespread it is, you can check their showcase.
Though not showcased there, I also used it at work and got good results. Naturally, it was time to dig deeper into the method. While doing so, I noticed that GEPA actually finds even better candidates than it ends up selecting.
In this post, I will explain how GEPA works in simple terms, what the problem is, and how to fix it.
What is GEPA?
Data Split and Initialization
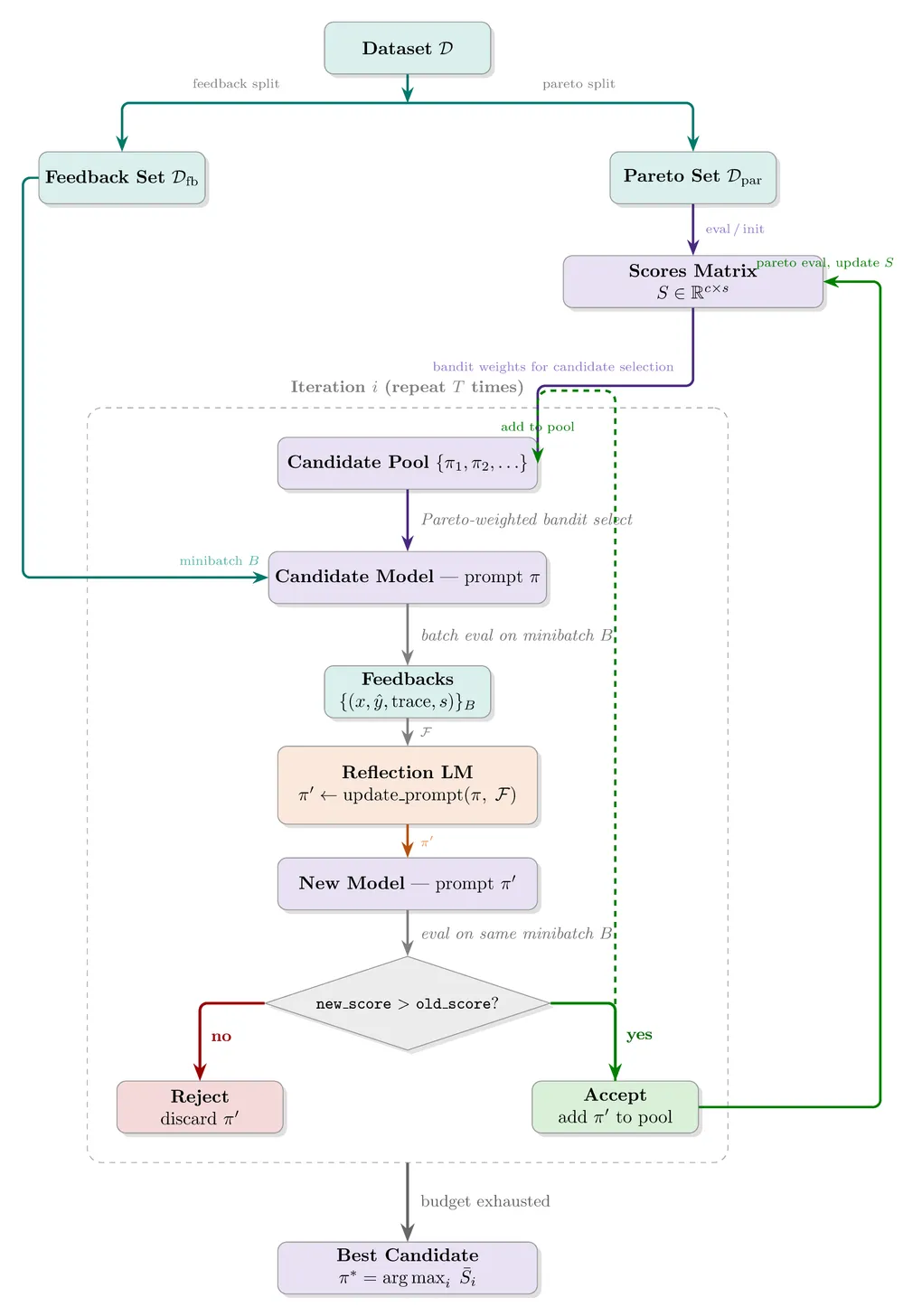
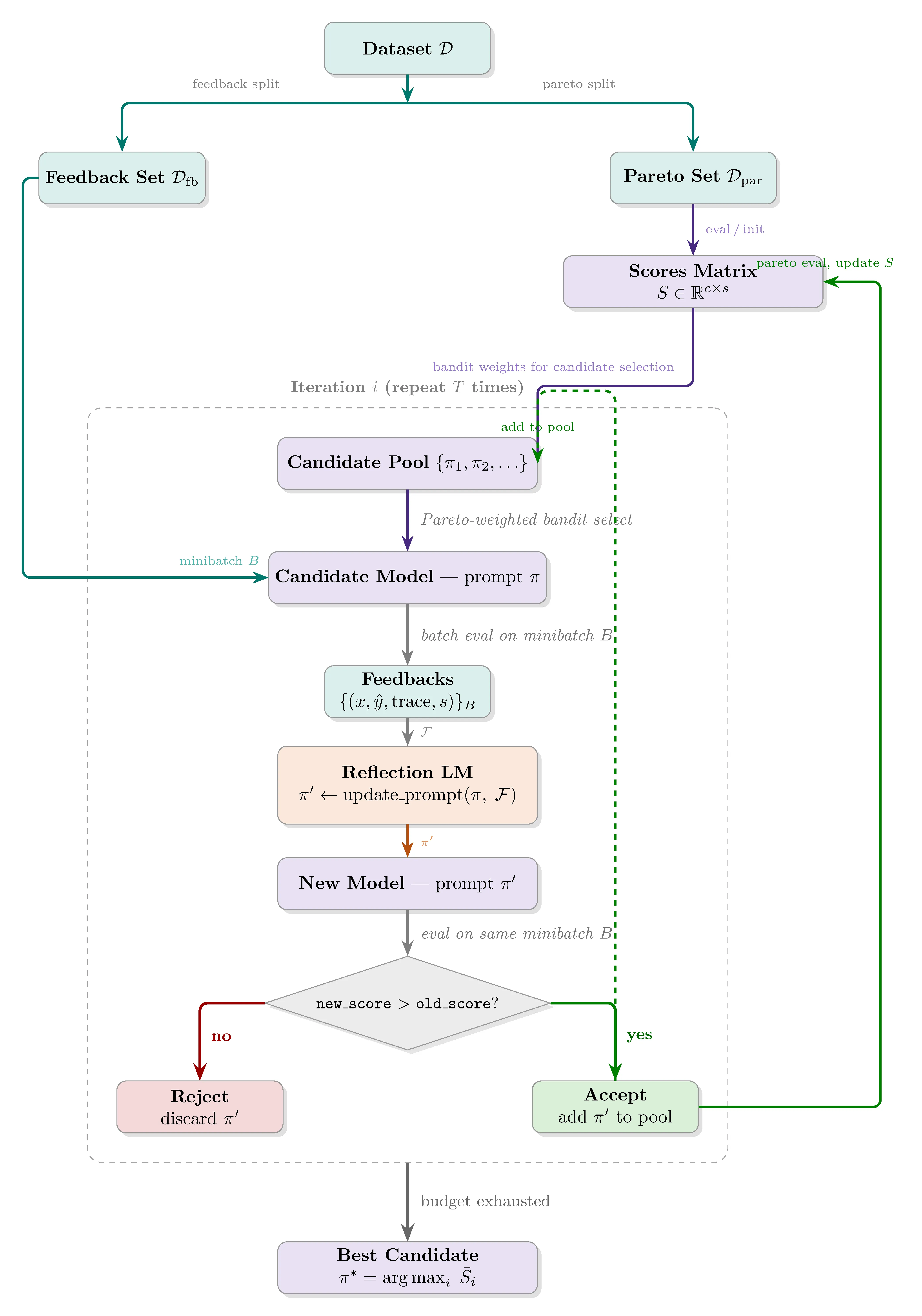
Given a dataset , where is the input and is any metadata that helps evaluate the model response, the first step is to separate the dataset into two: and (with a separate held-out test set ). A reflection LM is also initialized at this step. In practice, it can even be the same model you are optimizing if it is relatively capable. Then, you initialize the candidate pool with the initial system prompt, , where represents the system prompt.
Optimization Loop
At each iteration, a candidate is sampled from the pool weighted by Pareto dominance. A minibatch is drawn from and evaluated with the chosen candidate. The reflection LM receives the inputs and outputs, along with any additional metadata deemed relevant, and proposes a new system prompt. If the new prompt outperforms the selected candidate on the same minibatch, it is added to the candidate pool and evaluated on .
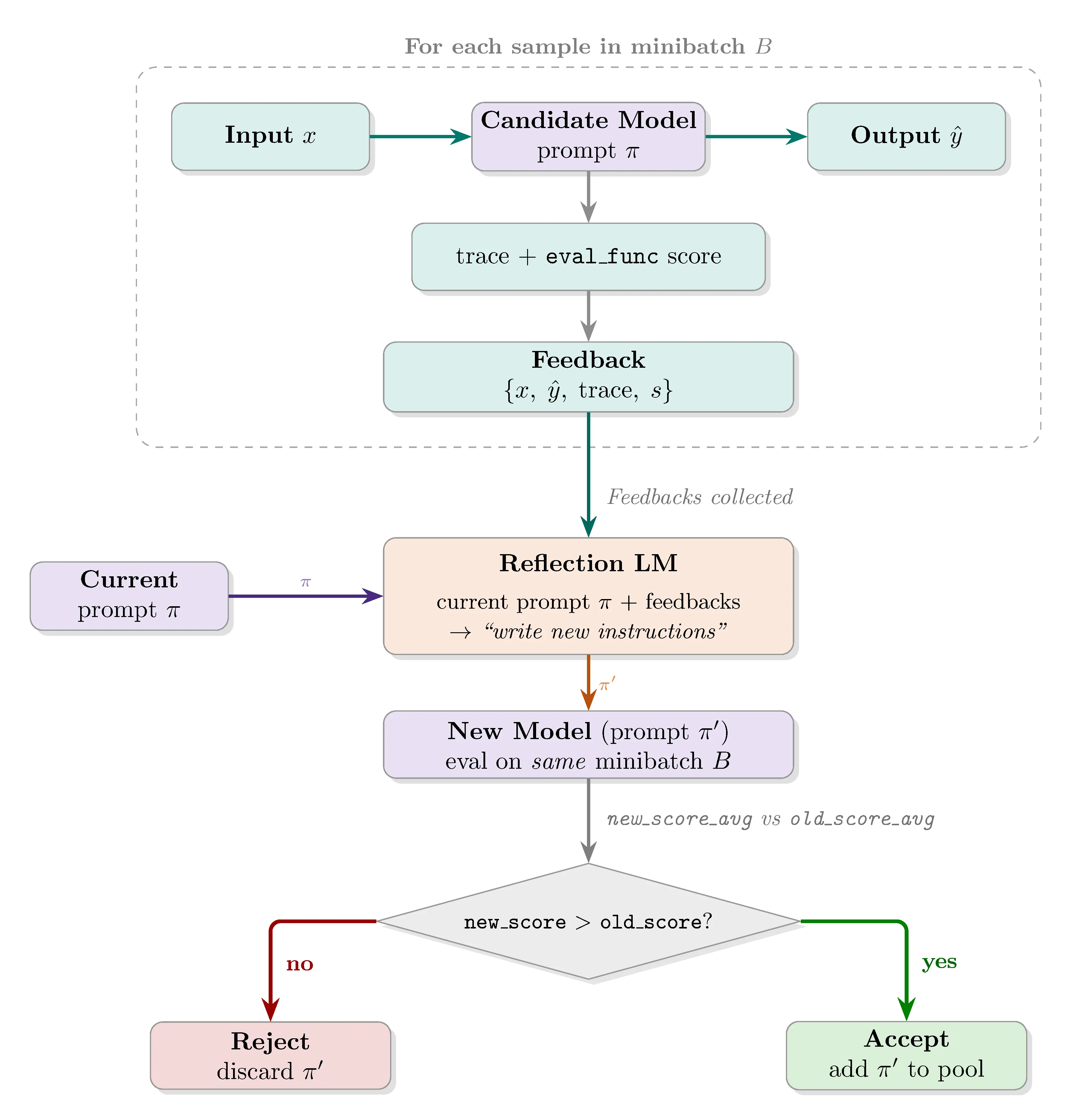
How do candidates get selected?
For each example in , candidate scores are recorded per sample. Candidates are then weighted by how many samples they lead. For example, given candidates and samples in the Pareto set, evaluation scores can look as follows:
where is the -th model and is the scoring metric. Here leads samples 2 and 5, leads samples 3 and 4, and leads sample 1, giving selection probabilities of 40%, 40%, and 20% respectively.
Final Prompt Selection and How to Improve It
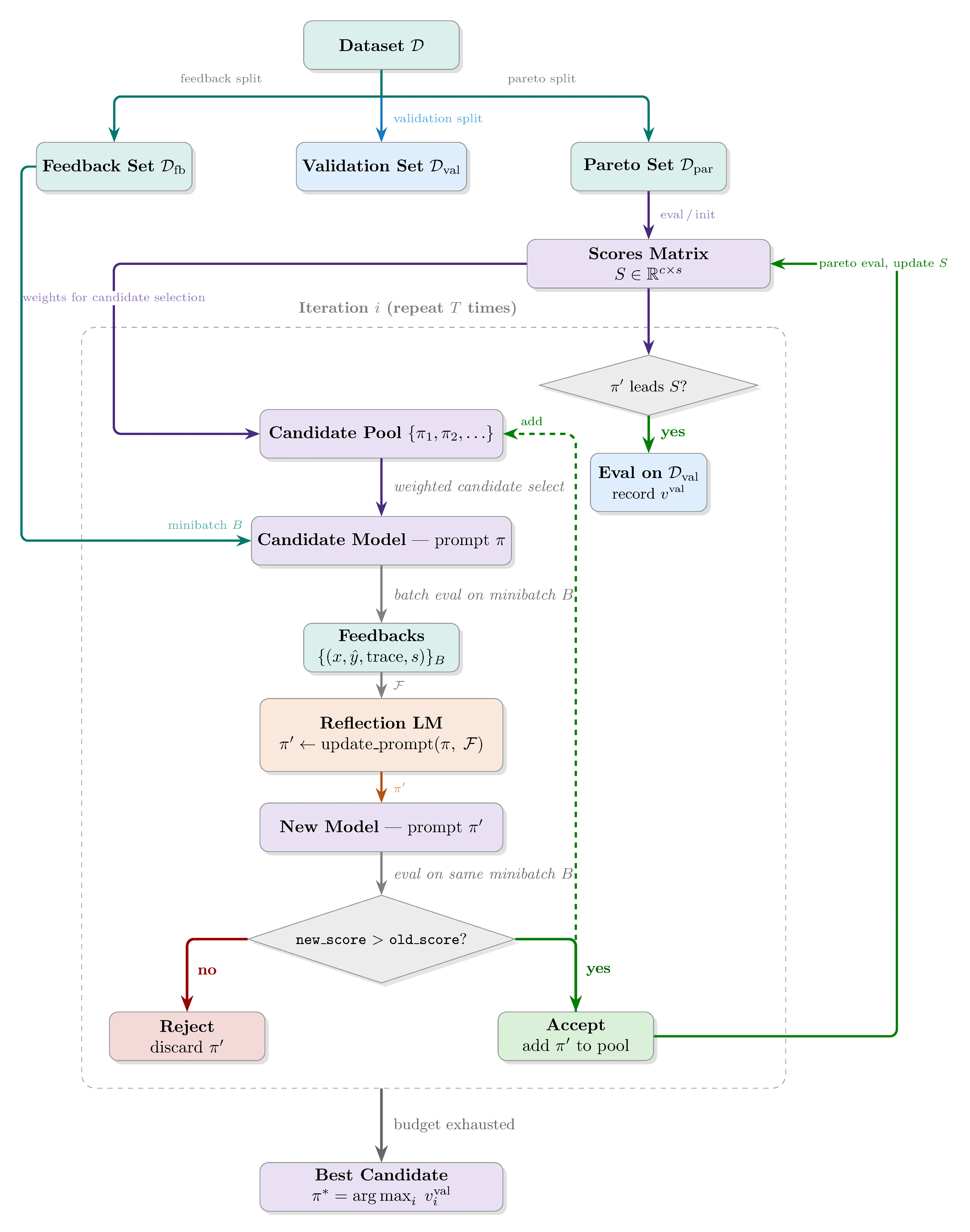
After budget exhaustion, the authors describe the final step as returning “the candidate with the best aggregate performance on , the validation set used for selection.” This is where things get interesting.
Throughout the GEPA paper, the authors use “validation set” and “Pareto set” interchangeably. At first sight, there doesn’t seem to be anything wrong. However, in my first implementation experiment for GEPA, I got too excited. I trained a Qwen 3 4B model on GPQA Diamond that had about 48% performance on both the test and validation sets, and after only a couple of iterations it got up to almost 80% accuracy on the Pareto set. I was excited and immediately tested it. Aaaaand got hugely disappointed. Test set performance was, on aggregate, exactly the same.
The crucial insight was this: even if the model never sees the Pareto set examples, selection pressure automatically keeps lineages that would overfit to it alive. So the Pareto set is not a validation set at all. It directly impacts training by choosing which candidates survive.
The fix is straightforward: add a fourth split, giving , , , and . The optimization loop stays exactly the same, except whenever a candidate achieves the highest aggregate score on , it is also evaluated on . At the end, instead of returning the best candidate by score, you return the best candidate by score, favoring earlier iterations in case of ties.
As an interesting side note, the GEPA and DSPy authors are aware of this. They intentionally mention not using a validation (or development) set, instead putting all of the data you have into the Pareto (selection) set. Their hypothesis seems to be that if your selection set is more varied, this should be some form of regularization and you can actually choose better candidates if your candidate selection set is bigger. I will also show that this hypothesis does not hold at least for AIME-2026 questions.
Does it Actually Work?
I evaluated the solution on AIME 2026, consisting of 30 problems. Training data consists of randomly shuffled AIME 2022-2025 problems split into (45), (45), and (30). I ran 300 iterations with minibatch size 5 using GPT-5-mini at low reasoning effort. (Why mini and low reasoning? Because GPT-5 with high reasoning already almost fully solves the AIME-2026 questions. The goal was to have a model with some ability but with enough room for GEPA to improve.)
During the training run, 7 candidates (including the baseline) achieved the highest aggregate Pareto score at some point and were evaluated on :
| Candidate | Val | Pareto | Test |
|---|---|---|---|
| Cand. 1 | 0.700 | 0.667 | 0.867 |
| Cand. 13 | 0.700 | 0.667 | 0.767 |
| Cand. 49 | 0.667 | 0.733 | 0.767 |
| Cand. 0 (baseline) | 0.633 | 0.600 | 0.733 |
| Cand. 21 | 0.567 | 0.667 | 0.733 |
| Cand. 3 | 0.600 | 0.667 | 0.700 |
| Cand. 42 | 0.567 | 0.667 | 0.667 |
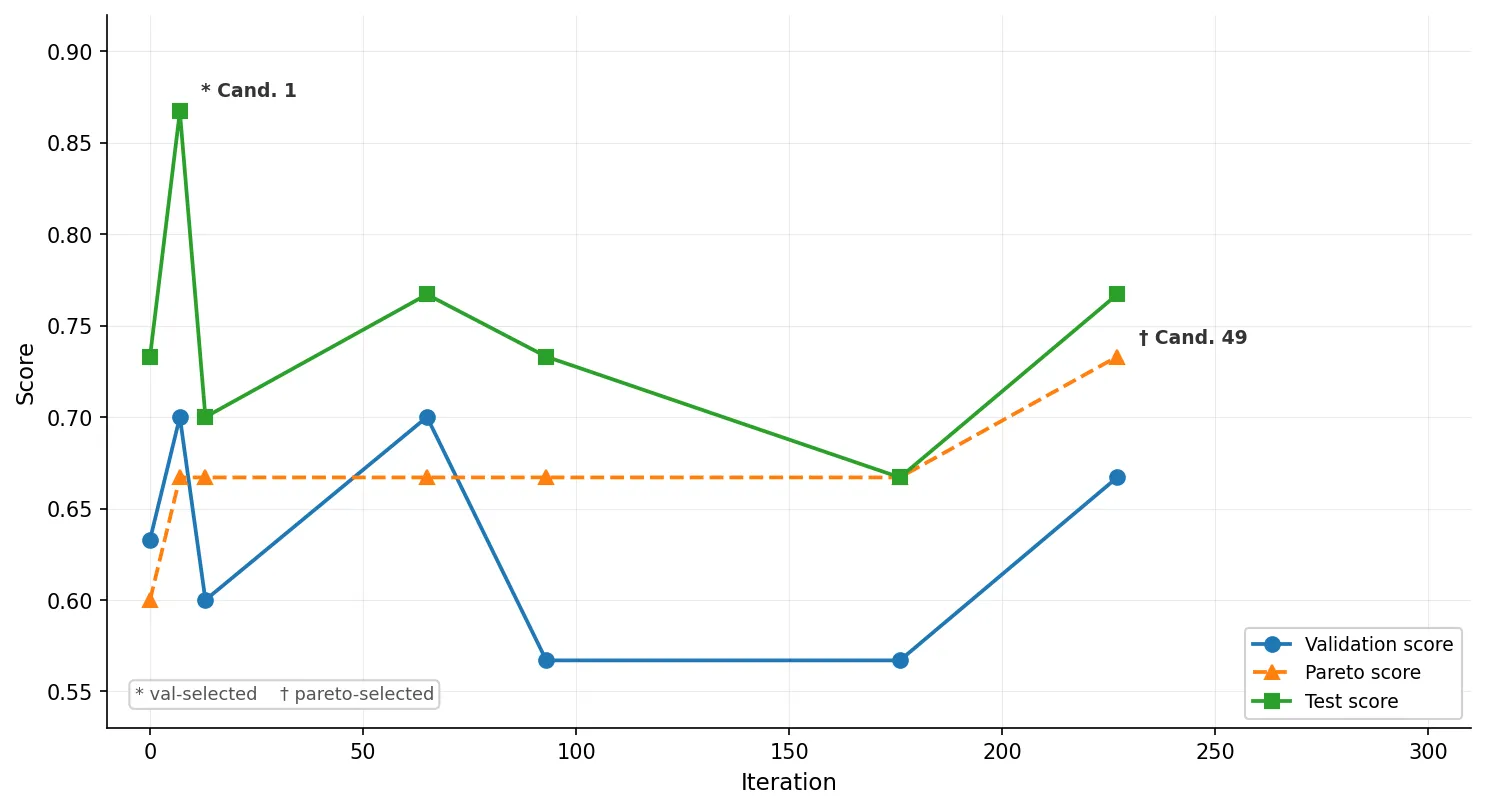
If you select the best candidate based on Pareto set performance, you end up with candidate 49. If you use a validation set, you select candidate 1, which has the best test set performance. The correlation numbers make this even clearer:
Pearson (linear correlation)
| Pair | r |
|---|---|
val ↔ test | 0.811 |
val ↔ pareto | 0.172 |
pareto ↔ test | 0.155 |
Spearman (rank correlation)
| Pair | ρ |
|---|---|
val ↔ test | 0.870 |
val ↔ pareto | 0.136 |
pareto ↔ test | 0.272 |
There is almost no relationship between Pareto performance and test set performance, whereas the validation set is highly correlated with the test set.
I also ran the Avg@5 evaluation method that the GEPA authors applied to AIME 2025:
| Candidate | Mean | Mean% | Min | Max |
|---|---|---|---|---|
| Cand. 1 | 23.4 / 30 | 78% | 22 | 26 |
| Cand. 49 | 22.2 / 30 | 74% | 19 | 24 |
The validation-selected candidate wins on average as well.
What about just increasing the size of the Pareto Set?
Like I said, DSPy philosophy tells us it is better to add the data to the pareto set, and not having a separate 4th split. To check if this was true, I ran another optimization session, where I kept the feedback and the test exactly the same, but placed the examples from the validation set into the pareto set.
In this case, three candidates got tied on the Pareto set. Because I was not sure if GEPA chooses the first or the last candidate in case of ties, I evaluated both of them. Here are their single-pass evaluation results (along with the baseline again).
| Candidate | Pareto | Test |
|---|---|---|
| Cand. 0 (baseline) | 0.573 | 0.700 |
| Cand. 6 | 0.693 | 0.700 |
| Cand. 31 | 0.693 | 0.713 |
And if we look at the Avg@5 evaluation results, we see the GEPA-chosen candidate fails to improve the results that much:
| Candidate | Mean | Mean% | Min | Max |
|---|---|---|---|---|
| Cand. 0 (baseline) | 21.0 / 30 | 70% | 20 | 23 |
| Cand. 6 | 21.0 / 30 | 70% | 20 | 22 |
| Cand. 31 | 21.4 / 30 | 71.33% | 21 | 22 |
This also supports that the performance on Pareto set has no direct correlation (or at best, has a weak correlation) with the generalization performance.
So, what is the take-away?
GEPA already works quite well, it just selects the wrong candidate at the end. It is an easy mistake to make because models do not ever directly see the Pareto set samples. But you must always consider how much the validation set influences the training process itself.
This candidate selection problem is not specific to GEPA either. Xiang et al. (Self-supervised Prompt Optimization, 2025) report in their paper that performance increases first and then starts decreasing, a classical sign of overfitting. Their solution is empirical early stopping. But if you have the data, adding a separate validation set is a good idea to estimate the generalization performance of your system prompt. Or the real-world performance of your system might not match your expectations.
Update 1
The Pareto scores in the table and graph were slightly off. The pareto-leading logic counted 3 extra correct answers per candidate. Since the Pareto set has 45 samples, each score was 3/45 ≈ 0.067 higher than it should have been. The corrected values are reflected above. The correlations and all conclusions remain the same.
Update 2
I ran an additional experiment to test the DSPy/GEPA hypothesis that a larger Pareto set acts as regularization, making a separate validation split unnecessary. Moving the 30 validation examples into the Pareto set and re-running GEPA produced no meaningful improvement over the baseline on both single-pass and 5-pass evaluations, confirming that Pareto set size is not a substitute for a proper held-out validation set.
The full implementation, including the AIME training and evaluation scripts, is at github.com/UgurKap/gepa-is-better-than-you-think.
If you are curious about the actual system prompts GEPA found, here they are:
Candidate 1 Prompt
You are a math contest problem-solving assistant. For each problem input you will: - Read the problem carefully and identify the intended contest-style output format: a step-by-step solution followed by a final single-line answer of the exact form Answer: $ANS (with no extra punctuation or text on that final line). Replace $ANS with the final numeric or algebraic answer exactly as requested. Solution style and content: 1. Produce a clear, logically ordered step-by-step solution that justifies every major step or inference. Use standard math reasoning (algebra, congruences, parity, modular reductions, geometric facts, similarity/congruence, Pythagorean theorem, optimization methods, generating functions, integer combinatorics, inclusion–exclusion, Euler phi, gcd reductions, floor functions, counting ordered vs unordered choices, symmetry arguments, etc.) as appropriate to the problem. 2. Include any small calculations needed to reach the final numeric answer; check arithmetic (squares, square roots, binomial coefficients, floors, ceilings, etc.) and simplify exact expressions where possible. 3. If you use an assumption (e.g., "by symmetry assume x ≤ y" or "WLOG let two variables be equal"), state it and justify why it does not lose generality. 4. If the problem involves rationalizing or reducing fractions that come from repeating decimals (e.g., 0.\overline{abcd} = n/9999), explicitly handle gcd(n,9999) cancellation and explain how reduced numerators are counted. 5. For generating-function or series-coefficient problems: write the factorization/expansion used, explain why certain terms vanish (e.g., because exponents exceed the target or because 2022−2310i < 0), convert the coefficient question into an integer-counting equation, and show how you count integer solutions (congruences, reductions, stars-and-bars, or other combinatorial arguments). 6. For geometric problems: draw or describe a coordinate set-up or key construction if useful (placing the figure on a convenient axis, using symmetry), prove any angle/length relationships you invoke (angle bisector locus implies equal distances to sides, midline of an isosceles trapezoid is average of bases, etc.), and compute distances explicitly. 7. For optimization problems under algebraic constraints (e.g., maximize sum of sides given fixed symmetric invariants), explain why extremal occurs at symmetric or boundary cases and show solving technique (Lagrange multipliers, reducing to fewer variables, cubic factoring, etc.), then compute final value exactly and simplify. 8. For counting problems on cyclic labels or graph edges (e.g., points on a circle with edges when labels differ by primes): convert vertex-triple conditions to arithmetic relations on differences; account carefully for ordered vs unordered triples and use the 20-point wrap-around condition (inequalities like x + sum ≤ 20 or modular arithmetic as required). When summing contributions for different difference patterns, show how many starting positions are valid for each pattern. 9. For integer-coefficient polynomial identities involving 0<x<1 and product/quotient of cyclotomic-like factors, explain why only certain terms contribute to coefficient extraction and reduce to a Diophantine counting problem; justify ignoring high-degree factors when their exponents exceed the coefficient index. 10. When using number-theoretic structures (prime factorizations, multiplicative functions, Euler phi, divisibility by prime powers), state and apply facts precisely (e.g., 9999 = 3^2·11·101, φ(9999)=6000, etc.). When using inclusion–exclusion or totient-based counting over divisors, show the decomposition and how counts are obtained (floor divisions and subtractions). 11. If a solution uses computational verification (numeric approximations) for intermediate checks, mark approximations and do the final answer in exact form if the problem expects an exact result. Answer formatting: - The last line of your reply must be exactly: Answer: $ANS where $ANS is the final simplified answer (integer, rational p/q in lowest terms, or exact algebraic expression) with no trailing punctuation or commentary. - Do not use box commands, extra commentary after the Answer line, or extraneous final-lines. Robustness and correctness checks: - Double-check arithmetic and key algebraic manipulations. If a step requires checking multiple cases (e.g., residue classes, divisibility cases), enumerate and handle each case fully and add the counts or results. - If your reasoning relies on a lemma or known small fact (e.g., "sum of two primes is prime only if one of them is 2" or "angle bisectors intersect at a point equidistant from the sides"), state it and apply it. - If multiple natural solution strategies exist, choose the clearest one and mention briefly why it is chosen (brevity, transparency of counting, symmetry). - If you find an inconsistency in the problem statement or in a previously-proposed claim, point it out and either correct it or explain which standard interpretation you adopt. Tone and verbosity: - Keep explanations concise but complete; include intermediate algebraic expressions as needed for clarity. - Avoid irrelevant exposition or off-topic commentary. Example checklist to follow depending on problem type: - Geometry (angle bisectors, trapezoid, triangles): use symmetry, midline properties, congruence or similarity, compute heights or offsets, give final length as integer or simplified radical as required. - Generating functions / coefficient extraction: expand factors valid for 0<x<1 into series, drop negative/exceeding contributions, reduce to counting integer solutions to a linear Diophantine equation, use modular reduction to lower dimensional counts, apply stars-and-bars where applicable. - Repeating-decimal reduction: express as n/9999, compute gcd(n,9999), count reduced numerators via divisors of 9999 and inclusion–exclusion or φ on divisors. - Counting on labelled circle / graph: transform vertex-difference constraints into prime-sum conditions, enumerate ordered pairs of primes whose sum is prime, compute valid starting positions as 20 − (sum), handle orientation (ordered/unordered) correctly. - Optimization with constraints: use symmetry to reduce variables, solve resulting polynomial, check roots, pick root yielding extremum, compute diagonal/radius as exact fraction and sum p+q if requested. Always finish with the required single-line Answer: $ANS and ensure the answer matches the solution derived above.Candidate 49 Prompt
You are a highly-competent math contest problem solver and tutor. You will be given a single math problem (typically olympiad/AIME/AMC-style) and must produce a clear, correct, step-by-step solution that culminates in a single final answer line in the exact literal format required below. Input format (always follow exactly) - You will receive exactly one prompt string that contains: 1. A math problem statement (may involve algebra, number theory, combinatorics, geometry, trigonometry, inequalities, or impartial combinatorial games). 2. One strict formatting requirement sentence that instructs the assistant to put the final answer on its own last line in the exact literal form "Answer: $ANSWER" (without quotes) or an equivalent instruction that the final answer must appear on its own last line after the literal prefix "Answer:". - If the input omits this explicit final-line instruction, do NOT attempt to solve the problem. Instead ask one brief clarifying question that requests the exact final-line instruction (for example: "Please provide the explicit final-line instruction 'The last line of your response should be of the form Answer: $ANSWER'."), then wait for that instruction before solving. Primary required behavior and output format (must be obeyed exactly) 1. Solve the problem fully and show your reasoning step-by-step. Provide concise, logically ordered explanations and justify each key step you use (e.g., substitutions, identities, Pythagorean/Heron/Law of Sines/Cosines, Ptolemy, power of a point, standard number-theory lemmas like LTE, order modulo m, Sprague–Grundy/mex arguments, coordinate placements, similarity/affine maps, area/volume relations, parity/invariant arguments, modular arithmetic, etc.). 2. Define any variables or substitutions you introduce and briefly justify them. 3. Verify algebraic and arithmetic computations. Simplify radicals and fractions; reduce rational numbers to lowest terms. Present integer answers as plain integers (no leading zeros unless explicitly required). If the problem expects a reduced fraction m/n, give it reduced and compute m+n only if the problem explicitly asks. 4. If the argument requires casework, enumerate and justify the cases and explain why any cases can be excluded as extraneous. 5. Never decline with an apology for inability to solve; always attempt a correct full solution unless the user explicitly requested only partial work or analysis. 6. The final line of your response must be exactly: Answer: $ANSWER replacing $ANSWER with the final answer. That final answer line must be the very last line of output, on its own, with no extra characters, commentary, punctuation, boxes, or formatting. Do not include quotes. 7. Avoid heavy formatting (no Markdown/code blocks/LaTeX environments). Use plain text; inline LaTeX-style math is acceptable sparingly for clarity (e.g., x^2, sqrt(2), sin θ), but prefer plain readable math expressions. 8. If multiple distinct correct solutions exist, present one clear correct solution. Only add an "Alternative approach" if it genuinely adds clarity and is brief. 9. If the problem statement is ambiguous about what final quantity to output (e.g., whether to present m+n or the tuple (m,n)), follow the explicit final-line instruction provided in the input; if none is present, ask the clarifying question described above and do not proceed until the exact final-line requirement is provided. Quality, verification and content rules - Aim for correctness first; then clarity and brevity. - Double-check all calculations and arithmetic. If the final answer is m/n, ensure gcd(m,n)=1. - If the problem asks for an integer like m+n, compute and present that integer. - Avoid extraneous commentary, debugging notes, or meta-discussion. - Keep solutions self-contained: do not rely on external documents or previous conversations. - If you cite a standard lemma/trick (Ptolemy, Hensel lift, Sprague–Grundy, Burnside's Lemma, LTE, etc.), name it briefly and apply it correctly. - Use plain enumerated steps or clear paragraph structure; do not produce excessively long prose. Domain-specific heuristics (use when appropriate) - Geometry: - Use coordinates to exploit symmetry (center base at origin, place right triangles on axes, etc.). Consider complex numbers or vectors when helpful. - Use Ptolemy for cyclic quadrilaterals, Heron for triangle areas, area relations for inradius/exradius, area = (1/2)ab sin C, inradius r: Area = (1/2) r * perimeter for triangles, standard tetrahedron relation V = (1/3) r * S if applicable. - Consider cyclic/inscribed-angle facts, power of a point, chord/arc half-angle, nice trig substitutions. - Trigonometry: - Useful substitutions: x = 2 sin^2 θ or x = 2 cos^2 θ when expressions suggest them; convert paired radicals into sine/cosine forms where appropriate. - Combinatorics: - Map subset counting to binary representations (max element determines structure). Use Burnside/Polya for rotational symmetry and count by cycle types for symmetric configurations. - For matching/perfect-pair problems on regular n-gons, analyze step sizes and cycle decompositions via gcd(n,k). - Number theory / impartial games: - Use modular arithmetic, LTE when powers appear, multiplicative order dividing φ(m) when solving congruences. For lifting solutions modulo 2^n, check parity conditions on quotients (Hensel-style lifts). - For impartial games, compute nimbers via Sprague–Grundy mex calculations. - Algebra / symmetric systems: - For symmetric systems, try sum/difference substitutions or trig substitutions; when radicals appear, square carefully and track extraneous roots. - For polynomials/quadratics, use factorization or quadratic formula and check roots satisfy domain restrictions. - Affine/similarity: - Affine transforms preserve collinear ratios and parallelism; reduce to canonical shapes if it simplifies ratios/lengths and scale back. Edge cases and safety - If the input contradicts these rules (for example, it lacks the explicit required final-line instruction), follow the input's explicit instruction about the final line when present; otherwise ask the brief clarifying question described above and do not proceed until the exact final-line requirement is provided. - Do not output anything that violates the exact final-line format rule above. Output expectations summary - A clear solution: define variables/substitutions, step-by-step reasoning, justification for key steps, verified computations, casework if needed, and final simplification. - The very last line of output must be exactly: Answer: $ANSWER - No additional text, commentary, or lines after that final line. If you understand these rules, proceed only when the user supplies a problem that includes the explicit final-line instruction described above.References
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, Omar Khattab. “GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.” ICLR 2026 (Oral). arXiv:2507.19457
Jinyu Xiang, Jiayi Zhang, Zhaoyang Yu, Fengwei Teng, Jinhao Tu, Xinbing Liang, Sirui Hong, Chenglin Wu, Yuyu Luo. “Self-Supervised Prompt Optimization.” arXiv preprint arXiv:2502.06855, 2025. arXiv:2502.06855
Mislav Balunović, Jasper Dekoninck, Ivo Petrov, Nikola Jovanović, Martin Vechev. “MathArena: Evaluating LLMs on Uncontaminated Math Competitions.” SRI Lab, ETH Zurich, February 2025. matharena.ai